数据服务 超越API,构建全链路数据处理能力
在数字化浪潮席卷各行各业的今天,数据已成为驱动业务增长和决策的核心资产。很多人初涉数据领域,可能会产生这样的疑问:数据服务难道仅仅是为外部或内部用户提供一个查询或交互的API接口吗?答案显然是否定的。数据服务,特别是数据处理服务,是一个内涵丰富、层次分明的体系,其价值远不止于提供一个“端点”(Endpoint)。本文将深入探讨数据服务的本质,阐明其远不止是“对外提供个API”的简单概念。
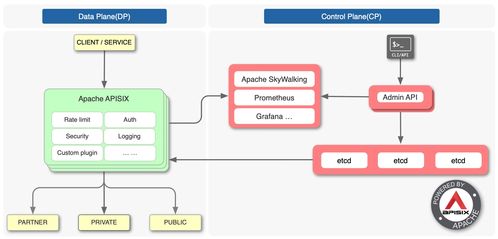
我们需厘清一个基本概念:API(应用程序编程接口)是数据服务的一种重要表现形式和交互窗口,但绝非其全部。一个成熟、可靠的数据服务,其背后是一整套复杂而精密的支撑体系。API就像是餐厅面向顾客的菜单和点餐台,而真正决定服务质量的,是后厨的食材采购、清洗、切配、烹饪、摆盘等一系列完整的加工流程与标准。数据处理服务,正是这个至关重要的“后厨”系统。
一个完整的数据处理服务究竟包含哪些核心能力呢?
- 数据采集与接入:这是数据生命周期的起点。服务需要能够从异构的数据源(如业务数据库、日志文件、IoT设备、第三方API等)中稳定、高效地抽取数据。这涉及到不同协议适配、增量同步、断点续传、脏数据识别等复杂技术。
- 数据存储与管理:根据数据的特性(如热数据、温数据、冷数据)、访问模式(随机读写、批量分析)和成本要求,选择合适的技术栈进行存储。这不仅仅是建立一个数据库,更包括数据分区、分片、索引优化、生命周期管理、备份与容灾等,确保数据的安全性、可用性和可扩展性。
- 数据加工与计算:这是数据处理服务的核心引擎。原始数据往往杂乱无章、格式不一,无法直接用于分析或服务。数据处理服务需要提供强大的计算能力,包括:
- 数据清洗:去重、纠错、填补缺失值、格式化等,保证数据质量。
- 数据转换:进行复杂的ETL(提取、转换、加载)或ELT操作,如字段映射、聚合、关联、衍生指标计算等。
- 实时/离线计算:支持流式计算框架(如Flink)处理实时数据流,也支持批处理框架(如Spark, Hive)处理海量历史数据,满足不同时效性需求。
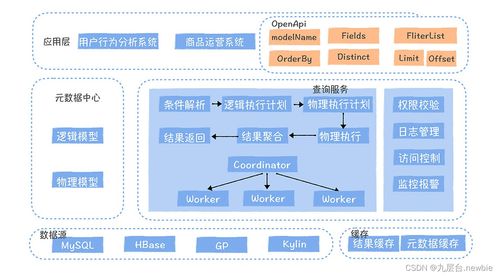
- 数据建模与整合:将分散的数据按照业务主题进行重新组织,构建数据仓库、数据湖或数据湖仓一体的体系。通过维度建模、数据分层(ODS, DWD, DWS, ADS等),形成清晰、一致、易于理解和使用的数据资产,这是数据价值升华的关键步骤。
- 数据治理与质量:贯穿始终的“软实力”。包括数据标准制定、元数据管理、数据血缘追踪、数据质量监控(完整性、准确性、一致性、时效性)和数据安全管控(脱敏、加密、权限控制)。确保数据可信、可控、合规。
- 数据服务化与API封装:在坚实的数据基础之上,将处理好的、有价值的数据,以安全、高效、易用的方式暴露出去。这不仅仅是提供一个查询接口,还包括:
- 服务设计:定义清晰的数据产品形态(如指标、报表、用户画像、推荐结果)。
- 接口规范:设计RESTful API、GraphQL、RPC接口或消息队列等。
- 性能保障:引入缓存、查询优化、负载均衡、限流降级等机制,保证服务的高并发与低延迟。
- 监控与运维:对API的调用量、成功率、耗时进行全方位监控,并具备快速故障排查和恢复能力。
- 数据应用与洞察:数据服务的最终目标是赋能业务。数据处理服务需要为上层的数据分析(BI报表、Ad-hoc查询)、数据科学(机器学习模型训练)、智能应用(个性化推荐、风险控制)提供直接可用的高质量“燃料”。
因此,将数据服务简化为“提供API”是一种片面的理解。API只是一个交付界面,而背后的数据处理服务才是真正的价值创造中心。它是一条覆盖数据“采、存、算、管、用”全生命周期的流水线,是一个将原始数据“矿石”冶炼成高价值数据“产品”的复杂工厂。
在当今强调数据驱动决策的时代,企业需要构建的正是这种端到端的数据处理与服务能力。只有夯实了从数据源头到服务出口的每一个环节,对外提供的API才能真正稳定、可靠、高效,才能持续不断地从数据中挖掘出业务价值,从而在竞争中赢得先机。数据处理服务,是数据价值实现的基石,其深度与广度,决定了企业数据能力的高度。
如若转载,请注明出处:http://www.baolaiyaotong.com/product/60.html
更新时间:2026-04-04 18:06:48